上课啦!Python爬虫系列课程之爬虫基础介绍
爬虫是什么?
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)。爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,并将数据存放起来加以利用。
爬虫的基本流程
用户获取网络数据的方式:
方式1:浏览器提交请求--->下载网页代码--->解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2,通过程序模拟浏览器,程序代替人工。流程如下:
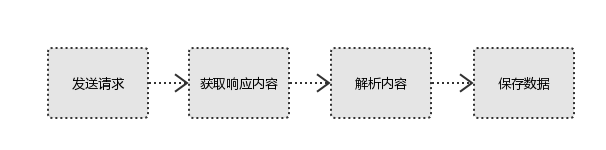
1、发起请求
使用http库向目标站点发起请求,即发送一个Request。
Request包含:请求头、请求体等。
Request模块缺陷:不能执行JS 和CSS 代码。
2、获取响应内容
如果服务器能正常响应,则会得到一个Response。
Response包含:html,json,图片,视频等。
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库等。
解析json数据:json模块。
解析二进制数据:写入文件。
4、保存数据
数据库(MySQL,Mongdb、Redis等)
本地文件
为什么选择Python爬虫
Python爬虫是用Python编程语言实现的网络爬虫,主要用于网络数据的抓取和处理。相比于其他语言,Python是一门非常适合开发网络爬虫的编程语言,大量内置包,可以轻松实现网络爬虫功能。
Python提供了较为完整的访问网页文档的API.
对比其他语言用Python开发速度快,代码简洁干净。
Python请求与响应
通过Python的爬虫包发送WEB请求,获取响应信息。
Python自带了urllib和urllib2爬虫包。urllib和urllib2都是接受URL请求的用于网络请求的相关模块,彼此各有利弊,urllib和urllib2通常一起使用。
而requests与scrapy是目前比较常用的Python数据采集包。也是大数据省赛、国赛数据采集步骤的指定考核范围(近几年的大数据竞赛数据采集步骤考核内容都是requests或scrapy)。
Python解析内容
解析内容就是将需求数据从响应的整体页面信息中提取出来的过程。
爬虫的数据采集可以帮助我们获取网站的页面内容,但页面内容会比较多并不是所有的页面信息都是我们需要的。页面的指定字段才是有价值的,才是我们想要得到的内容。对于获取的数据需要进行解析提取需求数据,正则表达式与xpath(lxml包)是目前比较常见的解析工具。
正则表达式是Python自带的包,Xpath需要安装lxml包。
正则表达式描述了一种字符串匹配的模式(pattern),可以用来检查一个字符串是否含有某种子串、将匹配的子串替换或者从某个字符串中取出符合某个条件的子串等。
例子:
import re
# 正则规则
nameReg = "title=\"(.+?)\""
# 整体信息
msg = ""
# 正则处理
msglist = re.findall(nameReg, msg, re.S | re.M)
# 提取内容
print(msglist)
结果:
['百度搜索']
XPath 是一门在 XML 文档中查找信息的语言。XPath使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
例子:
from lxml import html
xml_doc = """
first item
second item
third item
"""
# 转换格式,用于xpath获取指定内容
dom_tree = html.etree.HTML(xml_doc)
# xpath规则
msg = dom_tree.xpath("//li/a/text()")
# 循环获取的节点内容
for text in msg:
print(text)
结果:
['百度搜索']
first item
second item
third item
Python保存数据
将解析内容持久化,保存到数据库或本地文件。常见操作有MySQL保存与csv文件保存。
保存到MySQL:通过pymysql操作数据库,使用insert into语句插入数据。
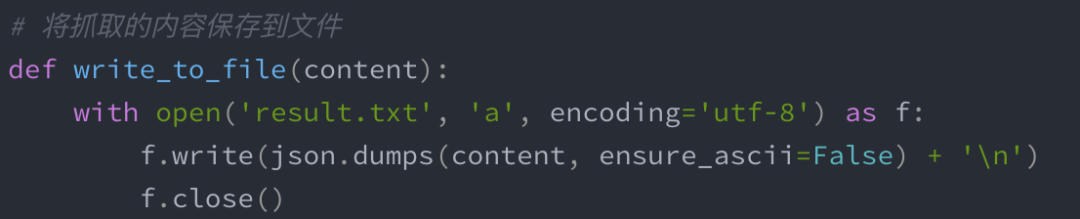
保存文件:file.write(“输出内容”)。
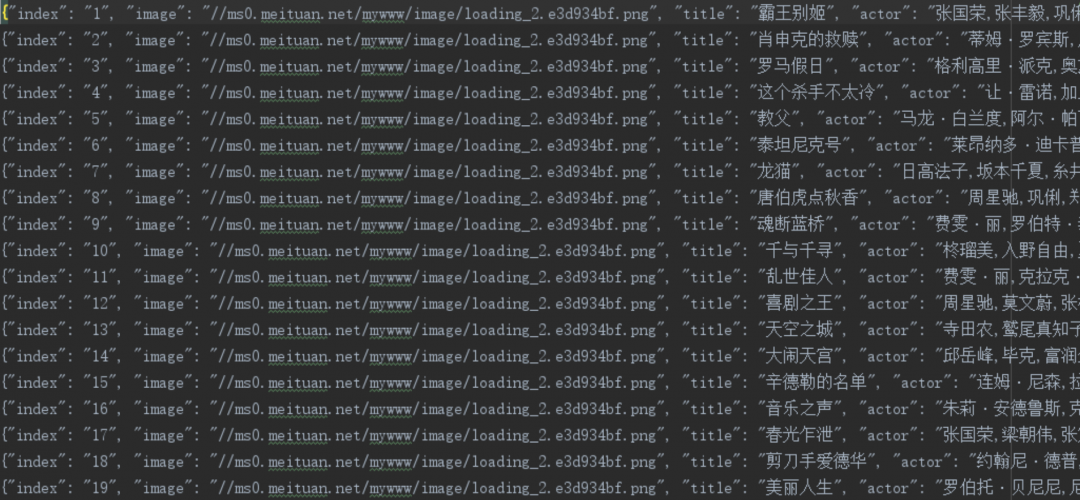
爬虫过程示例
此处只做演示,后续课程会讲解详细过程。
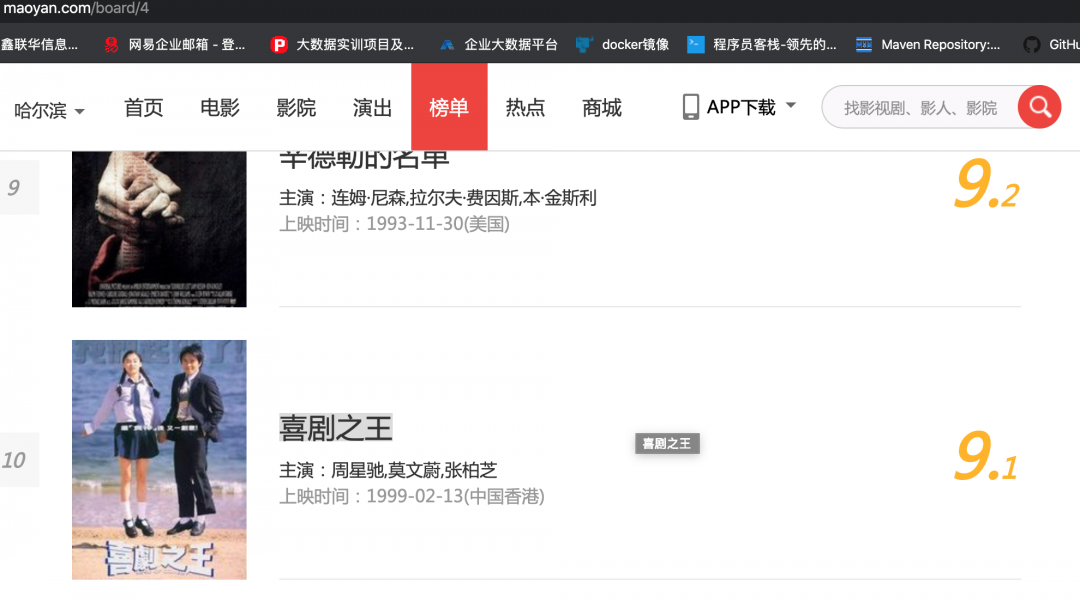
1、查看要访问的WEB页面。
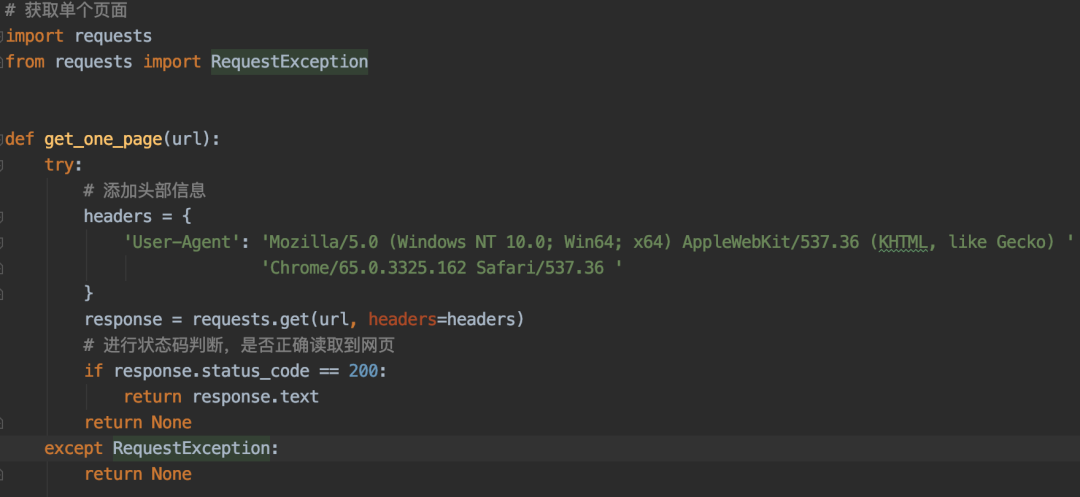
2、requests发送请求并获取响应内容。
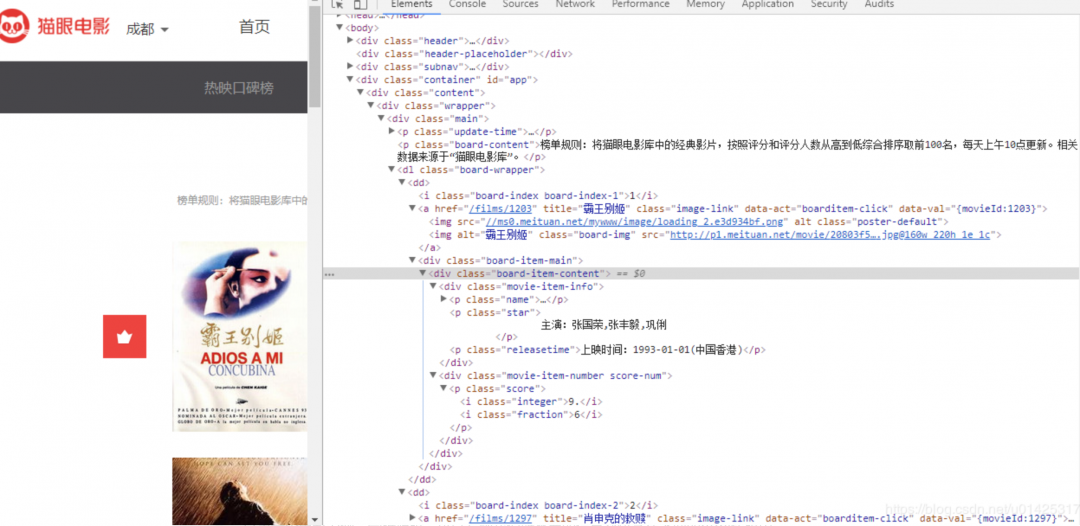
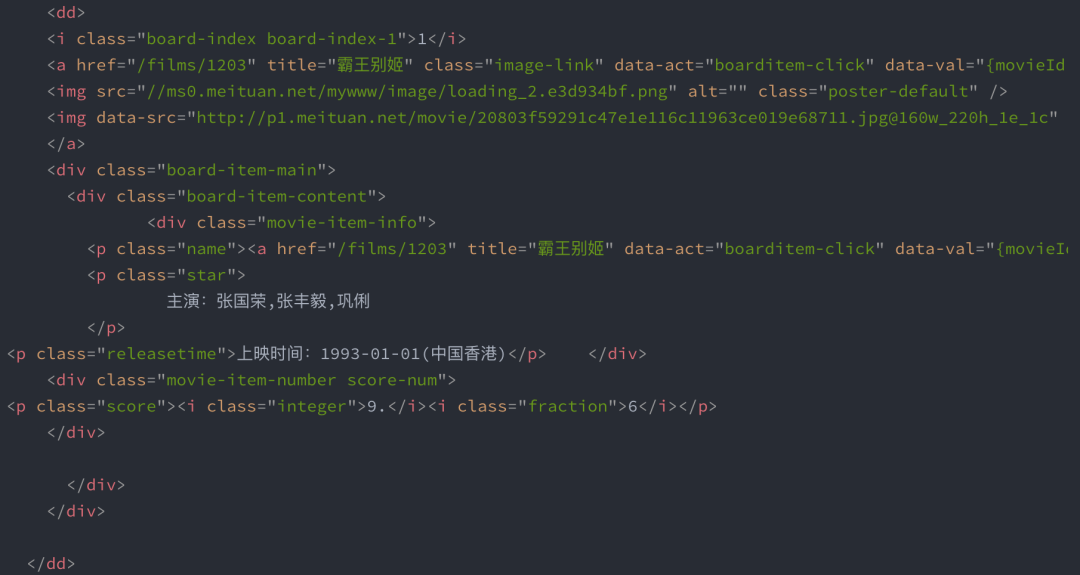
3、解析页面内容,提取需求字段。
4、保存内容